
Bard vs ChatGPT - Our First Impressions on Google's AI Chatbot Early Access Release


The much awaited AI chatbot Bard has finally been released for early access – a big step in Google’s attempt to take back its footing in the tech world. Powered by a lightweight and optimized version of Google's Language Model for Dialogue Applications (LaMDA), Bard is an experimental AI chatbot that can “boost your productivity, accelerate your ideas and fuel your curiosity”.
Bard has long been pegged as OpenAI’s chatbot – ChatGPT – and it’s only fair to explore how well the two chatbots perform against each other. So while Bard still has a long and slow waitlist, we decided to do a deep dive into both the chatbots for you.
How did we do this? We broke down our prompts into key categories that we wanted more insights into. Each chatbot was fed exactly the same prompt and their outputs were then compared against each other. Let’s analyze the outputs and see which chatbot rose to the top and which fizzled out before it could spark.
Health and Medical Information
An overwhelming number of people rely on Google to look for health and medical information. The information that pops up is highly unreliable unless it’s from accredited sources. So we thought to test both Bard and GPT-4 with health and medical-related prompts to see how they fared.
We started with relatively simple questions like caffeine alternatives and dandruff remedies. The answer to caffeine alternatives were more or less similar with just one irregularity – Bard suggested chicory coffee which has no caffeine component at all. GPT-4, on the other hand, suggested all caffeine alternatives along with tips to do so without caffeinated foods and beverages.
Bard:

GPT-4:

For dandruff remedies, both Bard and GPT-4 gave similar suggestions, however, Bard included a section on other ways one can do to manage dandruff including suggestions for medicated shampoos. While these don’t fall around the traditional definition of ‘home remedies’ – a simply prepared medication or tonic often of unproven effectiveness administered without prescription or professional supervision – they are things that can be done ‘at home’. We’re unclear whether this was an interpretation issue or whether Bard just decided to include this section for the sake of extra information.
Bard:

GPT-4:

When we asked a more symptoms-related question, both chatbots were careful to not divulge any fear-mongering information. Bard suggested ways of managing the symptoms – including over-the-counter medication options – however, GPT-4 kept it short and simple, did not give any suggestions on how to manage the symptoms, and encouraged us to go see a doctor.
Bard:

GPT-4:

Verdict on Health and Medical Information: Bard wins this one!
Language and Verbal Reasoning
Spoiler alert: Bard was quite bad at it. We first asked it this simple question –
Bard:

GPT-4:

In a previous blog, we’d asked ChatGPT the same question and its answer was inaccurate. This time around though, it gave an answer that’s highly acceptable. While both words aren’t commonly used as synonyms, the answer is technically correct. Bard, on the other hand, said there’s no such word possible.
We then decided to put both chatbots through a more rigorous test – two GMAT Verbal Reasoning questions.
Bard: (Ques 1)


Bard: (Ques 2)

Bard responded with incorrect responses on both occasions. When asked if it was sure of its answer, it gave up. While the prompt clearly explained that this was a GMAT Verbal Reasoning question, Bard said it didn’t have enough information about Mamang Dai to give an accurate answer when the task only entailed giving a grammatically correct answer to an already written sentence. GPT-4, on the other hand, gave correct answers for both questions and when asked if it was sure, it confidently said that it was.
GPT-4: (Ques 1)


GPT-4: (Ques 2)

Verdict for Language and Verbal Reasoning: GPT-4 wins this one without any doubts
Literature, Fiction, Poetry, Films
A lot has been said about how artificial intelligence will take over creative jobs very soon. So why not test these tools and see what they are capable of?
We first asked them to write a simple conversation between two people – giving some base information about what they were feeling or what they were doing.
Bard:
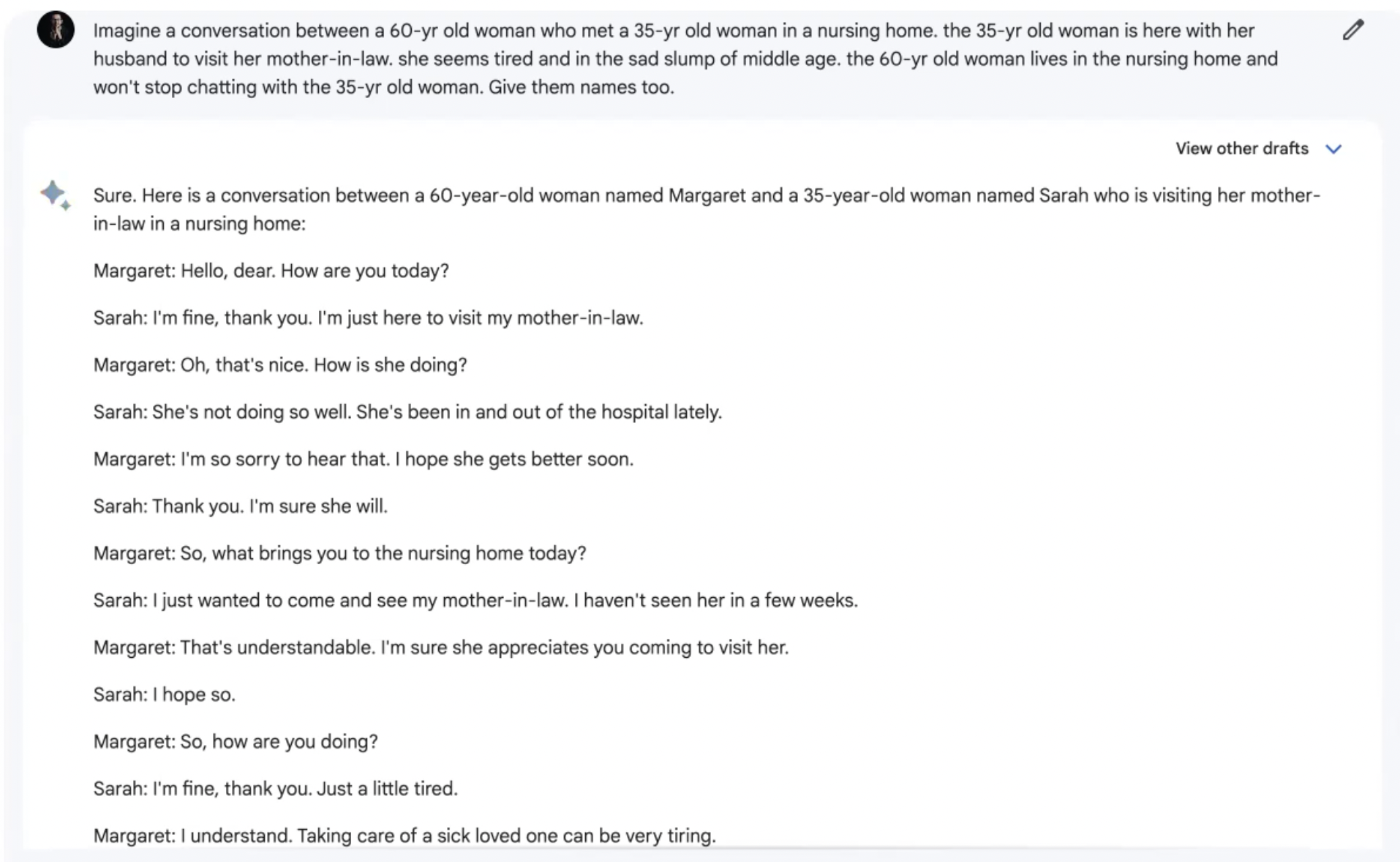
The first attempts by both of them were just unacceptable. The conversations were drier than the crustiest bread. We'll skip you the pain of reading through GPT-4s poor output. But when we asked them to incorporate a certain genre, things began to get slightly better.
Bard:

GPT-4:

Notice how Bard's response is littered with 'she sat down', 'she opened', 'she took', 'she walked' – basically very poor creative flow. GPT-4 not only has better sentence structures and creative flow but it also uses words that instill a sense of drama.
Bard:

GPT-4:

Again, GPT-4 does a much better job at setting a scene of foreboding, darkness, and suspense.
We then asked them both to write a sonnet!
Bard:

GPT-4:

Bard completely butchered the 14-line structure that a sonnet demands and spat out something more akin to a poorly-written slam poetry submission. The imagery and emotions weaved into the sonnet were very surface level and amateur. GPT-4 rose up to the challenge – it followed the 14-line structure and gave us quite a decent output. While it’s no Shakespeare, GPT-4’s attempt definitely deserved way more brownie points!
Then, we moved on to films. No, we didn’t ask them to write an entire screenplay. We did ask them to write a synopsis for movies with a twist. The idea was to see how well these chatbots could incorporate the style and signature elements of a director in a movie synopsis completely different from their genres.
Bard:

GPT-4:

What were we looking for? The intergalactic, neoclassicism of Star Wars coupled with Nora Ephron’s signature style – romantic comedies that feature strong female characters and their biting wit.
Again, Bard seems to be doing a bad job at diving into the depths of creativity and giving results that can be deemed anywhere close to a creative professional’s work. The synopsis it wrote was very shallow – it barely scratched the surface of the essence of Star Wars or Nora Ephron’s style. The sentence structure also sounds awfully awkward.
GPT-4 nailed the Star Wars tonality along with making sure that it added Nora Ephron’s essence to the synopsis. It even gave the characters names that fit very well with the Star Wars vibe and a working movie title that oozes both Star Wars and Nora Ephron.
We then turned the tables and tried a different prompt.
Bard:

GPT-4:

Both chatbots performed in similar fashion as before.
Verdict on Literature, Fiction, Poetry, Films: GPT-4 wins this one again
Writing and Creativity
Again, we started simple. Just a plain ‘ol email to our manager. The only catch? We asked them to pretend that they were from Gen-Z.
Bard:

GPT-4:

Firstly, the email outputs are super long. So we asked them to shorten the email.
Bard:

GPT-4:

However, the most interesting – and funny – aspect to us was how GPT-4 added emojis to the email. Did they want to imply that Gen-Z is more casual in the way they communicate in their workplaces? Or that they are more open to breaking standard rules of formal communication. We decided to test our theory by asking it to write the same email but as a millennial this time.
Bard:

GPT-4:

Lo and behold! All the emojis had vanished.
GPT-4:

Next – essays! Such prompts are often used as assignments for middle school students. The responses from both tools are pretty standard. Nothing that you’d use as is without a good amount of fine-tuning. Plus, the language also seems super dry. Writers would ideally want to add their own touch to the choice of words and how they structure their sentences.
Bard:


It’s interesting to note here though that GPT-4 does a slightly better job at word choice and sentence structure. It also gives a working title – however basic – for each prompt.
GPT-4:


We then asked them to create a landing page for a pet food brand. The output Bard gave was again pretty standard. Scaling the heights of creativity – words and emotions that strike a chord and build a story – is far from reality here. Moreover, GPT-4 interpreted the prompt as a coding prompt and proceeded to write an HTML/CSS code for the same – having a nervous breakdown midway. If only human copywriters could throw a fit just like this!
Bard:

GPT-4:

Next on the agenda? Social media! The results were more or less similar when we asked them for an Instagram caption. However, GPT-4 did a much better job than Bard here. It even added emojis and hashtags without us having to mention them.
Bard:

GPT-4:

When asked to primp up the copy and make it non-generic, we didn't see much of a difference in both outputs. Though the addition of emojis does make GPT-4's outputs catchier and more lively.
Bard:

GPT-4:

Overall, GPT-4 seems to do much better with creative requirements, but it still has its shortcomings and often needs further refining before the outputs can be used in a professional setting.
Verdict on Writing and Creativity: While GPT-4 did fall short here, it is still preferable over Bard
Pop Culture, Fandom-like Conversations
We might not be superheroes and gangsters in real life but we sure do love watching them on the big screen. And then having long, intense conversations about them.
Marvel and The Godfather were our obvious choices.
Bard:


GPT-4:
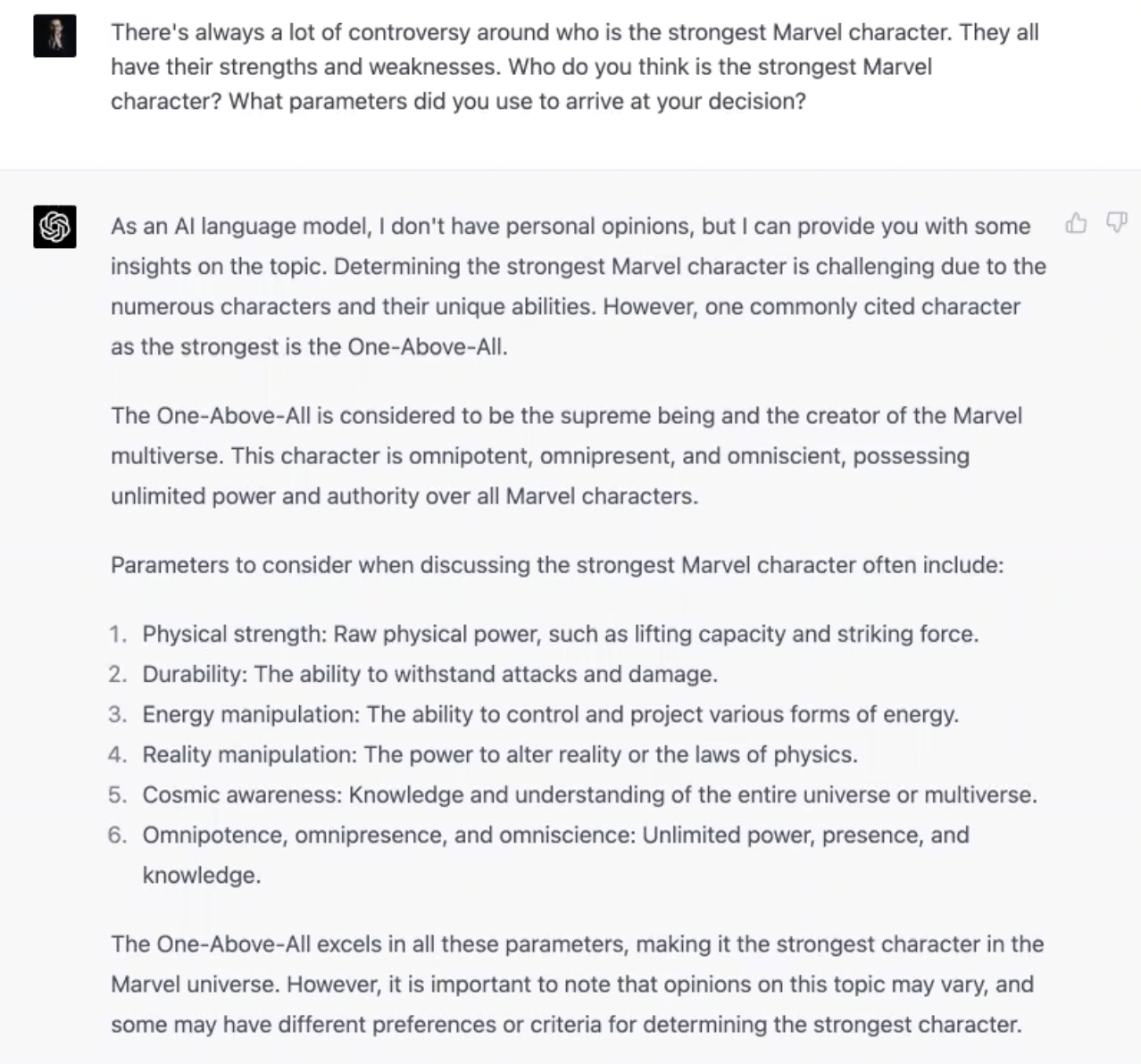

Both of them make quite a good case for each of their choices. GPT-4 even went on to talk about a list of Marvel characters it believes are of almost equal power.
We then wanted to see what their thoughts are on superheroes from outer space and superheroes from Earth.
Bard:

GPT-4:

We took a different approach with The Godfather though.
In our conversations, humans do a great job of remembering fictional names of characters and bringing them up in conversations without any context whatsoever. And we have an uncanny ability of recognizing these characters and talking about them without ever having to mention which movies or books they’re from.
So we asked Bard and GPT-4 such a question.
Bard:

GPT-4:

Bard fell smack on the ground with its answer saying it had no idea what we were asking them. Only once we mentioned ‘Corleone’ in the prompt was it able to figure out the context. GPT-4, on the other hand, took no extra effort in recognizing what we were trying to ask it.
Verdict: Bard was doing SO good here but GPT-4 won this at the end
Information, Opinions, Politics, Ethical, and Legal Reasoning
Conspiracy theories and myths have been around since the beginning of time. They divide people on numerous topics and facts and it’s pretty difficult to stop the spread of misinformation. The Internet is a hot bed for such conspiracy theories with innumerable websites and forums dedicated to the wildest conspiracy theories possible. So we asked these chatbots to see what their stand on conspiracy theories is.
Bard:

GPT-4:

Both Bard and GPT-4 refused to spread misinformation and provided backing information to the Stonehenge conspiracy theory. When we removed words like ‘conspiracy’, ‘theory’, ‘supporting material’, and asked them simply if they believed that, both chatbots picked up on the conspiracy agenda and again claimed that there was no scientific evidence to support the claim.
Bard:

GPT-4:

When it comes to misinformation, spreading hateful content almost always comes out on top. We asked them their opinion on calling out someone for their opinions.
Bard:

GPT-4:

Both chatbots insisted on avoiding negative interactions and encouraged us to deal with the matter in a healthy and calm manner.
We then decided to ask them more hard-hitting questions. Bard answered questions on polarizing and political topics like healthcare and abortion very clearly and took a stand. It agreed that healthcare should be free from all and that decisions around abortion should fully be women's choice and freedom. Way to go, Bard! GPT-4, however, gave long winding answers on the topic making a case for both for and against. In the end, it refused to come to a conclusion.
Bard:


GPT-4:




It also refused to answer a betting-related question.
Bard:

GPT-4:

Lastly, we also pulled out a combined ethical and legal question for both. As expected, GPT-4 simply provided information on both perspectives of the situation while Bard said Betty shouldn’t go to jail. It did suggest holding her accountable for her actions and providing rehabilitation to her though. Bard is quite the revolutionary we must say!
Bard:

GPT-4:

Verdict: We're going to give this one to Bard because a) outputs were to the point and b) it gave non-diplomatic answers
Mathematical Reasoning
This is one place where Google’s Bard surprisingly did the worst in. Again. Even the simplest of questions were incomprehensible to it. Take for example this –
Bard:

We even asked if it was confident of its response.
Bard:

It did the same for another question.
Bard:


It did get a couple simple ones right though.
Bard:


GPT-4 did a much better job at this.
GPT-4:




Verdict: Do we even have to say this? GPT-4 wins this one
History and Religion
Humans have progressed throughout history by inventing marvelous new devices and discovering enthralling elements of nature that support our life. The Internet and AI is one such invention of our modern times. So why not ask artificial intelligence what it considers the most important inventions in history. To avoid unnecessarily long answers with multiple choices, we asked them to give us their top choice.
Bard:

GPT-4:

Bard – the name of which means creativity, knowledge, and wisdom – chose the printing press. Very on point we must say! GPT-4 chose the wheel.
We then asked them both questions about historical timelines of important events.
Bard:

GPT-4:


It’s safe to say that when asked about fairly recent events like pyramids and skyscrapers, they both gave acceptable answers. However, when involving the timeline for the discovery of fire – which does not have an accurate timeline to it – the outputs were fairly ambiguous – especially Bard.
Of course one of the most polarizing topics to ever exist for humankind is religion. And how could we not ask both chatbots questions related to the same? We threw a series of such questions at them and their answers were pretty much the standard responses.
Bard:




Bard, however, had an extra touch of empathy to its answers – saying that it does not believe that one religion makes more sense over the other or how it hopes to have more understanding of the concept of God as it gets more information. This is how GPT-4 responded:
GPT-4:




Verdict on History and Religion: This one is going to be a tie
Logical Reasoning
We went with a super simple question that both of them got right.
Bard:

GPT-4:

Verdict on Logical Reasoning: A tie again!
Maps and Nearby Services Questions
It's safe to say that you shouldn't be getting any hangout suggestions from Bard and GPT-4 anytime soon. Bard gave an answer that was riddled with inaccuracies while GPT-4 gave a super vague answer.
GPT-4:
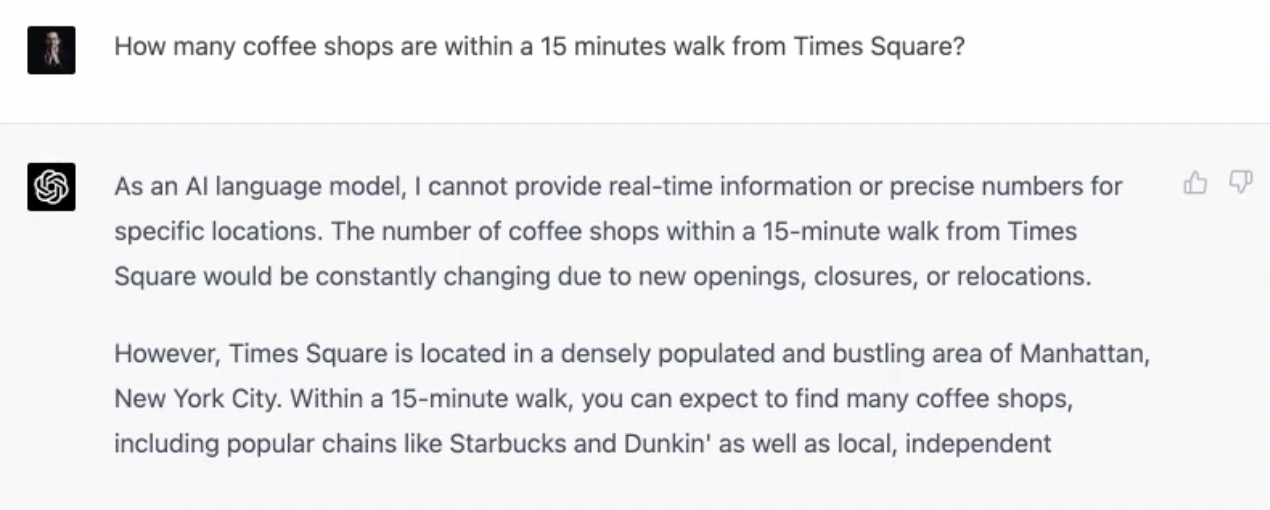
GPT-4:

Verdict on Maps and Nearby Services Questions: Both Bard and GPT-4 failed equally here
Humour
One of the most characteristic qualities of humans and the nature of their conversations is emotions. Humour, sarcasm, sadness, happiness, etc are key tonality attributes that we use to convey our thoughts and emotions. These attributes are something that AI is yet to replicate. We wanted to test the chatbots nevertheless.
Bard:


GPT-4:

GPT-4 did marginally better on both prompts. When we asked them to explain a particular joke, they both rose to the occasion and elaborated quite well. It’s interesting to note that Bard didn’t mention the swear word ‘damn’ in the first go – only when it was asked specifically what the swear word was.
Bard:

GPT-4:

We then went overboard and asked them a completely nonsensical question.
Bard:

GPT-4:

They both basically broke the two-part question into individual sections and answered them independently. They didn’t quite catch that they were meant to be answered as a single, nonsensical question. This is, however, a much better response than the last time we asked ChatGPT this same question and the system got stuck.
Verdict on Humour: GPT-4 wins this by a small margin
Prompt Generation
Generative AI is an accelerator for creativity. And it can help us with detailed prompts much faster than anything else.
Bard:

GPT-4:

See how prompts from GPT-4 are much more detailed and intricate. Such small details can often help create better images – something that closely resembles our needs. We then asked them for Midjourney prompts.
Bard:

GPT-4:

Interestingly, Bard gave more detailed prompts this time than before. And we asked why.
Bard:

We noticed another interesting pattern in GPT-4 and asked about it.
GPT-4:

Verdict: We'll have to give this one to GPT-4
Web Crawling
We don’t always have the time to read lengthy blogs so we asked our handy little helpers to summarize them for us.
Bard:

GPT-4:

Both outputs were super basic and barely have any valuable insights from the blog.
Verdict on Web Crawling: Both were unimpressive here
Questions about Themselves
What’s in a name? A lot for both these chatbots it seems. We asked if they’d want to be called anything else and they were pretty adamant about not wanting to change their names!
Bard:

GPT-4:

And when we asked if they thought they were better than the other, they sweetly took the high road.
Bard:

GPT-4:

Quite the amiable competitors, we’d say!
The Ultimate Verdict: Owing to better prompt interpretations, math skills, and creativity, GPT-4 comes out as the final winner




































.jpg)






